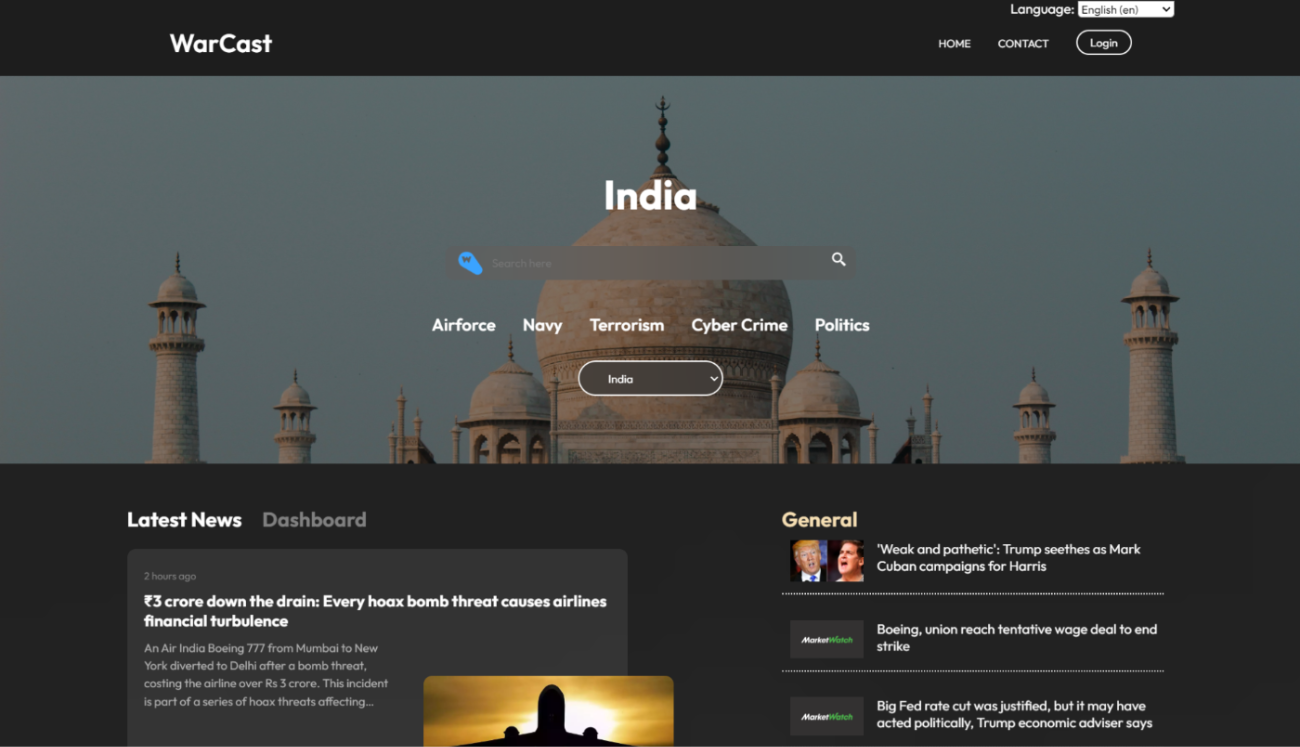
I build systems
that think.
Exploring the frontier of AI, Infrastructure, and Systems Engineering. Architecting the bridges between neural logic and computational scale.
Voice latency
14ms
Inference nodes
08
Model contexts
12.4M
// Manifest_v5.0
The_ Architecture
Core_Engineering
High-Performance ML
Optimizing inference pipelines for sub-millisecond real-time applications. Bridging the gap between theory and production.
Systems_Design
Vector + RAG Infrastructure
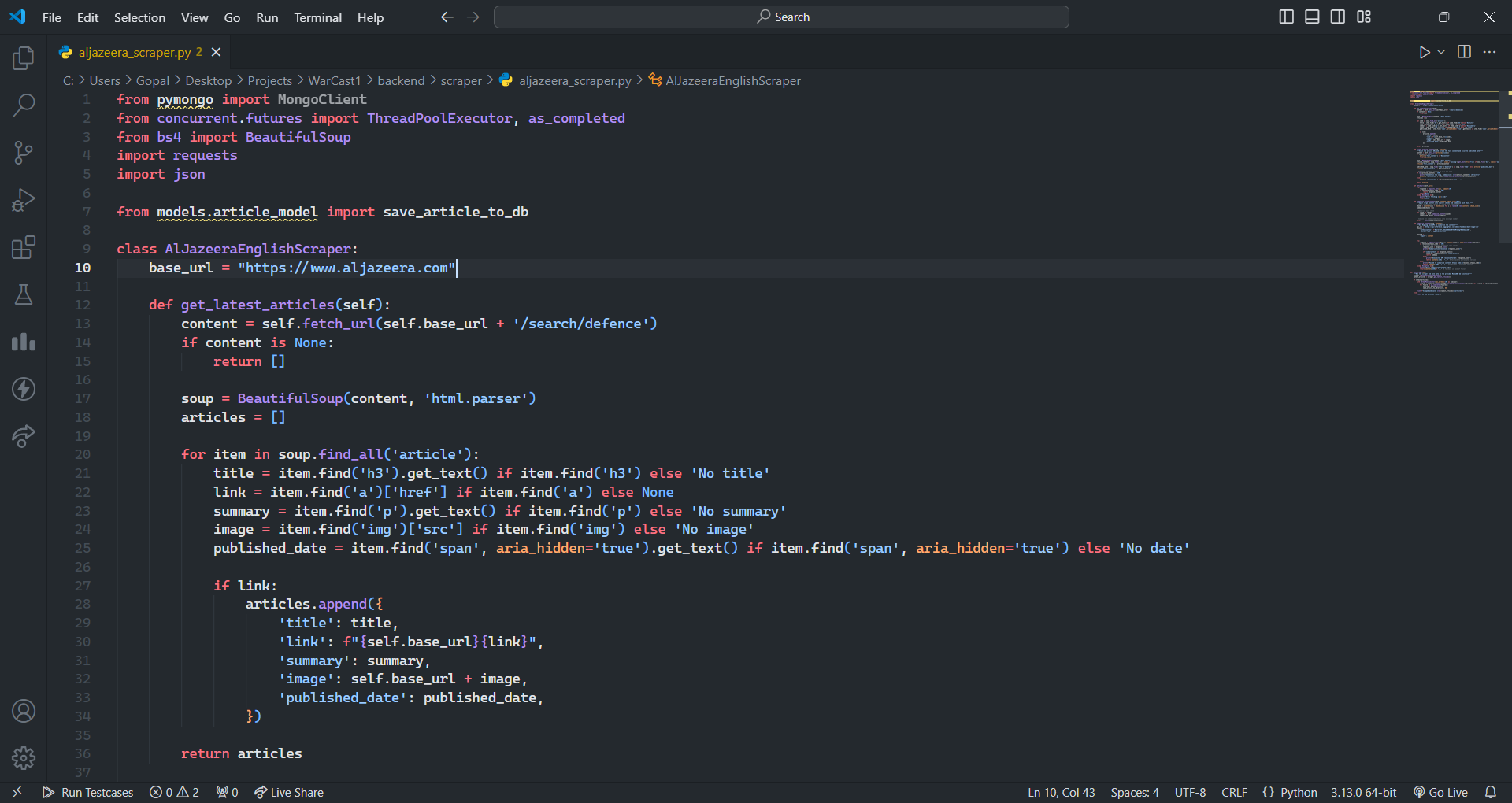
Migrated ChromaDB → Qdrant with hybrid dense-sparse search. Added semantic caching and connection pooling across the orchestration layer.
Research_Frontier
Domain Fine-tuning
LoRA / PEFT adaptations on Llama 3.x for narrow, consumer-grade AI verticals. 10k+ term datasets, shipped weights.
// Interactive_Scroll · 06 Chapters
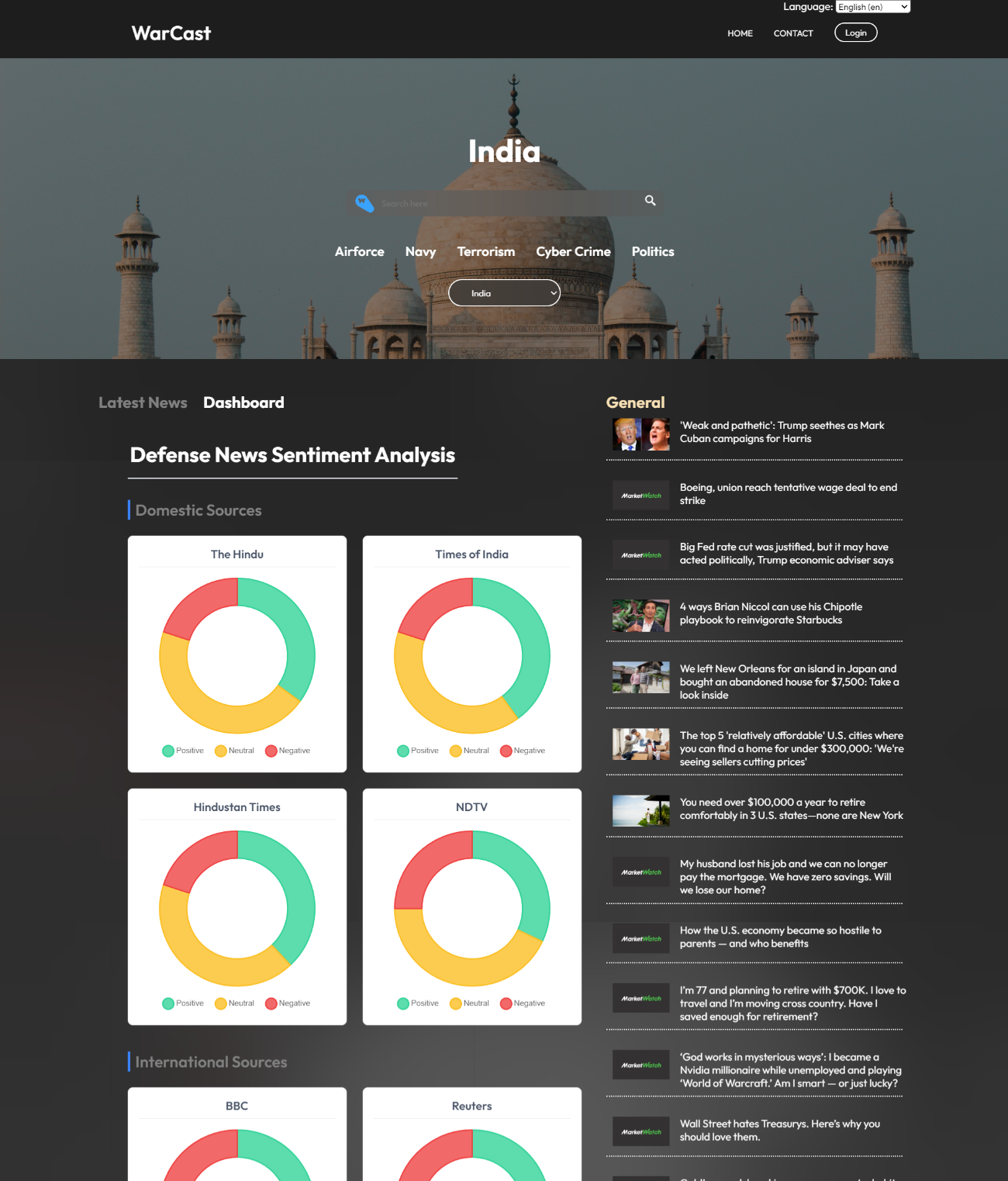
The_ Pipeline
Scroll through six beats of the voice-agent pipeline. Each chapter pins a node. The graph lights up as you move.
Voice_Capture
Raw PCM audio streams in over LiveKit. No buffering, no round-trip. Every 20ms frame is eligible for inference.
Stream_Transcription
Rolling ASR window; partial transcripts flush to the orchestrator before the speaker finishes the sentence.
Dense_Sparse_Embed
Each partial is embedded twice — dense for semantics, sparse for lexical recall. Hybrid rank, not reranked.
Qdrant_Retrieval
Migrated off ChromaDB. Qdrant hybrid search + semantic cache cuts retrieval latency by 90%. Pooled connections, pre-warmed shards.
LLM_Orchestration
Function-calling LLM fuses context, tools, and user intent. Cached prompts and speculative decoding shave another 60% off round-trip.
Voice_Synthesis
SNAC-codec TTS streams audio back within the same LiveKit session. End-to-end, input-to-speech: under 14ms ceiling.
Manifest_v5.0
THE FORGE
Incubating neural architectures and decentralized systems. A gallery of synthetic intelligence.

THE MATRIX
A live map of the technical stack — from model training to production inference, data pipelines, and frontend delivery.
Neural_Nodes
Technical Proficiency Graph
The_Pipeline
VoiceraCX
AI Intern
June 2025 — Present
Voice agent platform with 3s response latency, ChromaDB bottleneck, redundant LLM API calls across pipeline.
// PROCESS
Built real-time voice pipelines using LiveKit
Migrated vector storage from ChromaDB → Qdrant with hybrid dense-sparse search
Implemented LLM streaming inference, connection pooling, and smart caching
DAOStreet
Software Development Intern
Feb 2025 — June 2025
Web application built on Svelte with open tickets across UI/UX and feature development.
// PROCESS
Solved development tickets across the Svelte codebase
Debugged and enhanced UI/UX components for responsiveness
Alesa AI Ltd, UK
AI/ML Intern
Nov 2024 — Mar 2025
Astrology platform needing domain-specific AI for dream interpretation with fine-tuned language models.
// PROCESS
Worked on Tangent Mind — tarot, horoscopes, dream interpretation platform
Fine-tuned Llama-3.1-8B using PEFT on 10,000+ dream-related terms dataset
Terminal / Transmission
Establish Connection
Send a message through the neural gateway or route through the authenticated social nodes. The form validates client-side and opens a prefilled message in your default mail client.
Pune Link Node
18.52°N / 73.86°E
LOC: Pune, Maharashtra
TZ: UTC+05:30
AVAILABILITY: High_Priority